









A question I’m asked more and more often by clients and partners alike is, ‘How can I make sense of my large qual data sets?’ With less emphasis on data collection and much more on the interpretation of market research outcomes it’s an industry quandary that won’t go away any time soon.
Large or big qual data sets tend to be even more unstructured and unwieldy than their smaller counterparts. If you are lucky you are trying to make sense of a response to a specific verbatim in your survey. If you are unlucky you have been handed a scrape of customer reviews or social media content in relation to a brand, product or service all of which contain vast contextual variation. Thankfully, as the volume of qual research data available to us has increased so have the tools to assist in its analysis.
| Tweet This | |
| Big qual data sets mean big qual data analysis tools |
What is Text and Sentiment Analysis?
I’m going to focus on text and sentiment analysis, or opinion mining applications for big qual in this blog - The process of using computational techniques to extract, classify, and evaluate opinions expressed in text form. In this process unstructured text is classified into categories (opinion and fact) and degrees of positive and negative expression are extracted from the opinions.
Text and sentiment analysis can reveal:
- Whether comment sentiments correlate with NPS scores
- How strongly customers feel about your brand
- Whether your customers feel positively or negatively about your brand
A prerequisites before we proceed! In order generate actionable insight from this type of analysis you need text data that:
- References the product or service by name specifically
- Contains an opinion which can be allocated a positive or negative sentiment
- Is shared by a target market representative
- Is timely (a customer review dating back 10 years is not going to support current objectives!)
A ‘Big’ Qualitative Data Set
It’s worth defining at this point what we mean by ‘big’ / ‘large’ with reference to qual data sets. Computational aids to text and sentiment analysis are extremely effective for data sets in their 1,000s - 2,000 to 100,000+ comments from a relational database management system. For the most part, it is still advisable to use your brain’s processing power for the analysis of smaller qual data sets - comments in there 100s. The brain is currently the only machine that combines the range of complex rules required for truly emphatic qual data interpretation – when a machine supersedes the human brain in this regard we will be the first to let you know!
For a nice summary of the benefits and drawbacks of sentiment analysis take a look at: Can Text and Sentiment Analysis Tools be Trusted to Interpret Human Data? Being aware of the drawbacks outlined by Charlotte Pearson here is the key to success. As she explains and I completely agree, text and sentiment analysis tools are a fantastic supporting technology for market researchers. As a general rule, their operation and outputs must be humanly monitored to ensure accurate interpretation. Quality checks should be run on big qual data sets prior to analysis too (what length of comment is acceptable, etc.).
| Tweet This | |
| Text and sentiment analysis tools are a fantastic supporting technology for market researchers |
7 of the Best Text and Sentiment Analysis Tools for Big Qual
When you are happy with your big qual data set specifications and comfortable with your supervisory strategy, here is a selection of the best text and sentiment analysis tools on the market to get you started with automated analysis.
This one has to be my favourite! Mainly because you can add the plug-in to Excel and I’m very comfortable working in Excel spreadsheets! You can also access Semantria on a pay-as-you-go basis, making it much easier to trial for your use case.
Semantria is a really handy tool for organising text data into themes, entities and categories and sentiment scoring. I was impressed with its accuracy and additional data manipulations were very easy thanks to the Excel plug-in. Like all analytic software applications you need to invest a bit of time setting it up so that it understands what you are looking for, but it’s time went spent.

Repustate has a text categorisation API. This one is for the slightly more technically minded researcher who can engage with and write a bit of Python code to create custom sentiment rules.
Talking to other users of Repustate the key drawback is that much of your data may fall into a category of ‘sentiment neutral’. However, with topic detection as well as the ability to ‘read’ emojis, the system is very good at revealing the unknowns that we are looking for in qual data analysis. If you are worried that you are missing some vital information on specific experiences in relation to NPS scores, this is the program to run your verbatims through.
3. SmartboardMR
An in-house tool that we use all the time here at FlexMR is SmartboardMR. When participating in a SmartboardMR task customers are invited to specify the sentiment behind their comments. This prohibits any interpretive margin of error, a unique attribute removing the need for human intervention in the automated sentiment analysis of large or small qual data sets alike.
SmartboardMR is a great tool for making sense of customer feedback in relation to specific image-based content. If you want a clear understanding of the impact of your new website design, ad, promotion, packaging; of any customer facing creative use this tool from the outset. Get your customers to do the work of categorising and sentiment tagging whilst having a lot of fun!
4. FlexMR
Another text and sentiment analysis functionality we employ regularly in-house comes courtesy of our platform wide software functionality. Ideally suited to large qual data sets created by community panels; common themes, sentiments and tags defined by you are tracked long term. Graphical summaries of mood and sentiment are just a few clicks away allowing for the close monitoring of customer, brand and product experience trends.
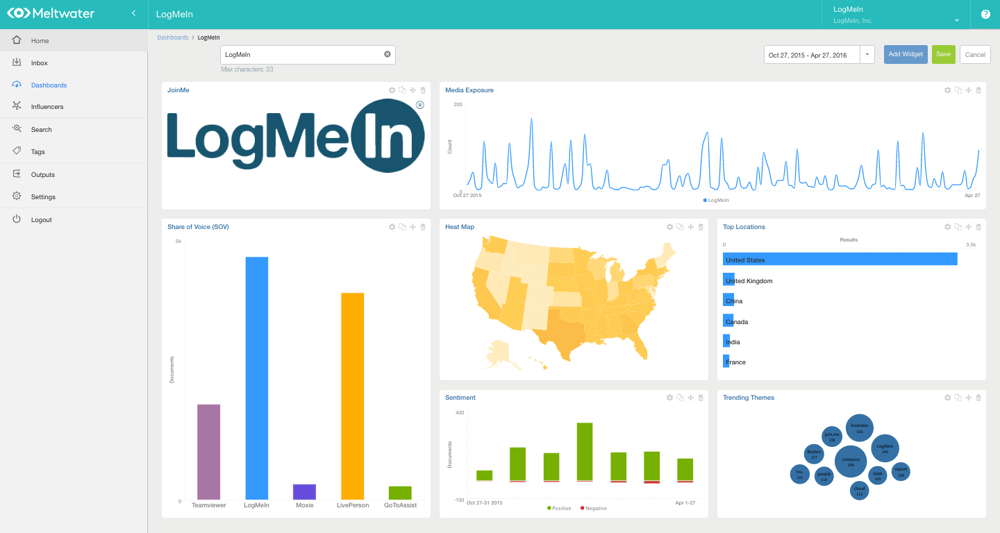
Meltwater is a comprehensive social media intelligence tool. In terms of sentiment analysis it works well, analysing the social media comments posted across multiple networks in relation to your business live. It’s definitely a great application for marketers, as well as tracking sentiment it also graphically summarises a whole host of other important information including what’s being discussed, by whom, and post exposure. The only downside is price. Meltwater is quite a big investment, so perhaps only justifiable for brands with a lot of consumer buzz, i.e. immense qual data sets.
RapidMiner offer a text analytics extension that allows you to analyse large sets of text data with respect to sentiment. I’ve heard a lot of good feedback about RapidMiner so felt it should be included here. I am not a regular user however and I found it really difficult to familiarise myself with the tool and functionality. Because of this I don’t think it’s a great standalone application but I’d love to hear from any RapidMiner users who have views to the contrary?
Finally, I’d urge the most sophisticated of qual researchers to engage with the SoDash, an innovative AI powered platform for social media analysis and customer experience management. Among other things SoDash ‘listens’ to a really wide range of online qual sources, then filters and tags for categorisation and sentiment. Its reach certainly gives you the confidence that you are not missing any important conversations surrounding your brand.






